About

PhD Candidate at RMIT University & the ARC Centre for Excellence in Automated Decision-Making and Society (ADM+S) | ADM+S Australian Search Experience 2.0 | Sessional Tutor for Psychology
Computational Models of Cognition | Resource-Rational Analysis | Sequential Latent-state Learning | Human-Computer Interaction
Polarization | Misinformation | Belief-updating | Fact-checking
The goal of my research is to understand how people learn and revise beliefs when time, attention, and computation are limited, and to use this understanding to design sequences of information that optimize learning under those constraints. I compare cases when learners begin with similar versus varied prior beliefs, asking how these starting points shape the ordering of items that yields the greatest learning for the least effort.
My current case study is political messages and news items, especially content that can mislead or provoke strong emotion. Using large-scale online experiments, I manipulate sequence features and measure when people shift their level of attention from intuitive judgments to focused deliberation, and how beliefs change in response.
To do so, we model how exposure history builds and tunes cached stimulus→response mappings, or habits that tune compact, structure‑aware policies that can be executed rapidly without reconstructing the full causal model on every trial. The guiding assumption is that such models are candidates for capturing human behaviour because they allow us to think about judgments in terms of the optimal solutions to the problems the human mind faces, which in the case of online environments, is hypothetically to determine the cues which are most conducive to quick judgment. If attention and computation are limited, people want to attain a strategy that functions well across environments and so store coarse predictive categories, or, defaults used when the context is ambiguous. Crucially, these coarse categories often track stereotypes about the speaker, their motivations and what political or social groups they belong to, biasing decision-making towards these cues.
Algorithmic feeds now structure much of human information access, necessitating an investigation that formalizes these environments. Different feeds expose people to different statistics, including those that frequently surprise to those that consistently affirm. These regimes modulate attention and memory and, in ways that we do not yet fully understand, increase cognitive load and degrade efficiency. We specify rules for these dynamics, with the aim of embedding learner models into information systems to enable adaptive placement of corrections or explanations when they can most effectively disrupt habitual responding and encourage planning.
Using a psychological method to increase performance of LLM for relevance judgement and ranking tasks (2025)
Summary and links coming soon.
When order shapes belief: sequence design for bounded agents (2025)
People rarely encounter information in isolation. Instead, they encounter it through algorithmic feeds that embed items within sequences and contexts that shape their salience, credibility, and integration with prior beliefs. We argue that human learning from recommender systems and the ways it may differ, can be understood by considering credibility as a computational problem of inference over time. The learner must identify reliable cues and sources, allocate attention, and update beliefs under constraints, which constitutes a computational problem that the human learner is optimized to detect and exploit. We claim that this problem acquires a rough solution from three fundamental control systems that the brain uses to maximize functioning across two desirable but competing performance dimensions: speed-accuracy, stability-flexibility, and generalization-multitasking. If improvements on one predictably degrades the other, then sequences that push the system toward speed, stability, or divided attention should yield predictable biases in belief updating. These trade-offs shape belief updating under sequenced exposure and serve to explain common findings in the misinformation and digital persuasion literature.
Clickbait amplifies partisan influence in headline truth judgments (2025)
Statements conveying news are presented with varying quality. Sensational, or ‘clickbait’ news is considered untrustworthy because they add cues distinct from the headline’s factual content. The specific nature and consequences of those cues for evidence processing are not yet understood. Competing accounts hold that sensational formatting either flags uncertainty and prompts more effortful scrutiny, or increases cognitive load and pushes reliance on partisan heuristics. In total, 80 participants from the U.S. judged the veracity of 64 headlines, varying in political congruence (congruent/incongruent) and truth (true/false), and were randomly assigned either to view clickbait or neutral formats. Results showed that both accuracy and response time exhibited a significant three-way interaction among style, congruence, and truth. For the clickbait condition, judgements aligned more strongly with political congruence, leading to more correct judgements for aligned headlines and fewer for conflicting ones. This pattern weakened under neutral formatting. A hierarchical drift-diffusion model indicated that clickbait changed how evidence was accumulated, less from cues about truth and more from partisan fit, without making people more cautious or pre-biased at the start.
Making accuracy easier: credibility perceptions as a latent cause assignment problem (2025)
The challenge of identifying reliable content amid widespread falsehoods requires a capacity for well-calibrated credibility judgments. We propose that humans address this challenge using statistical learning-the same cognitive process that helps us acquire language and recognize patterns. However, this adaptive mechanism may backfire in algorithmically curated information environments, leading to increased polarization and susceptibility to misinformation. We first outline a latent-cause model of credibility perception, which broadly describes the impact of structure learning, allowing people to categorize information based on recurring patterns (source identity, emotional tone, in-group signals) and then use these categories as shortcuts when evaluating new information. While this process is cognitively efficient, it can make users more vulnerable to misinformation that matches their learned patterns and more resistant to corrections that violate them. We present a Bayesian framework linking environmental statistics to belief formation, propose three testable predictions, and outline experimental protocols for studying these phenomena in controlled settings.
Confidence as inference over time: the effects of sequences on misinformation susceptibility (2025)
Overview and preregistration link coming soon.
Offgrid online: visualizing the environmental cost of everyday computation (2025)
Offgrid Online is a browser extension that visualizes the environmental cost of everyday digital activity. Every time a user searches the web or uses AI tools, it impacts a digital forest, trees are cut down, and a furnace burns, measuring the energy and environmental resources consumed. The forest reflects a user's digital footprint in real time. But users are also empowered to counteract this by donating to ecological charities, and so they can regenerate their forest and watch trees grow back, skies clear, and wildlife return. This project acts as a participatory artwork, interactive data visualizer, and behavioural feedback tool. Offgrid Online visualizes emissions and ties restoration to everyday behaviour. The result is a responsive forest that makes people's environmental data personal and changeable.
ADM+S Symposium — Automated social services: Building inclusive digital futures (2025)

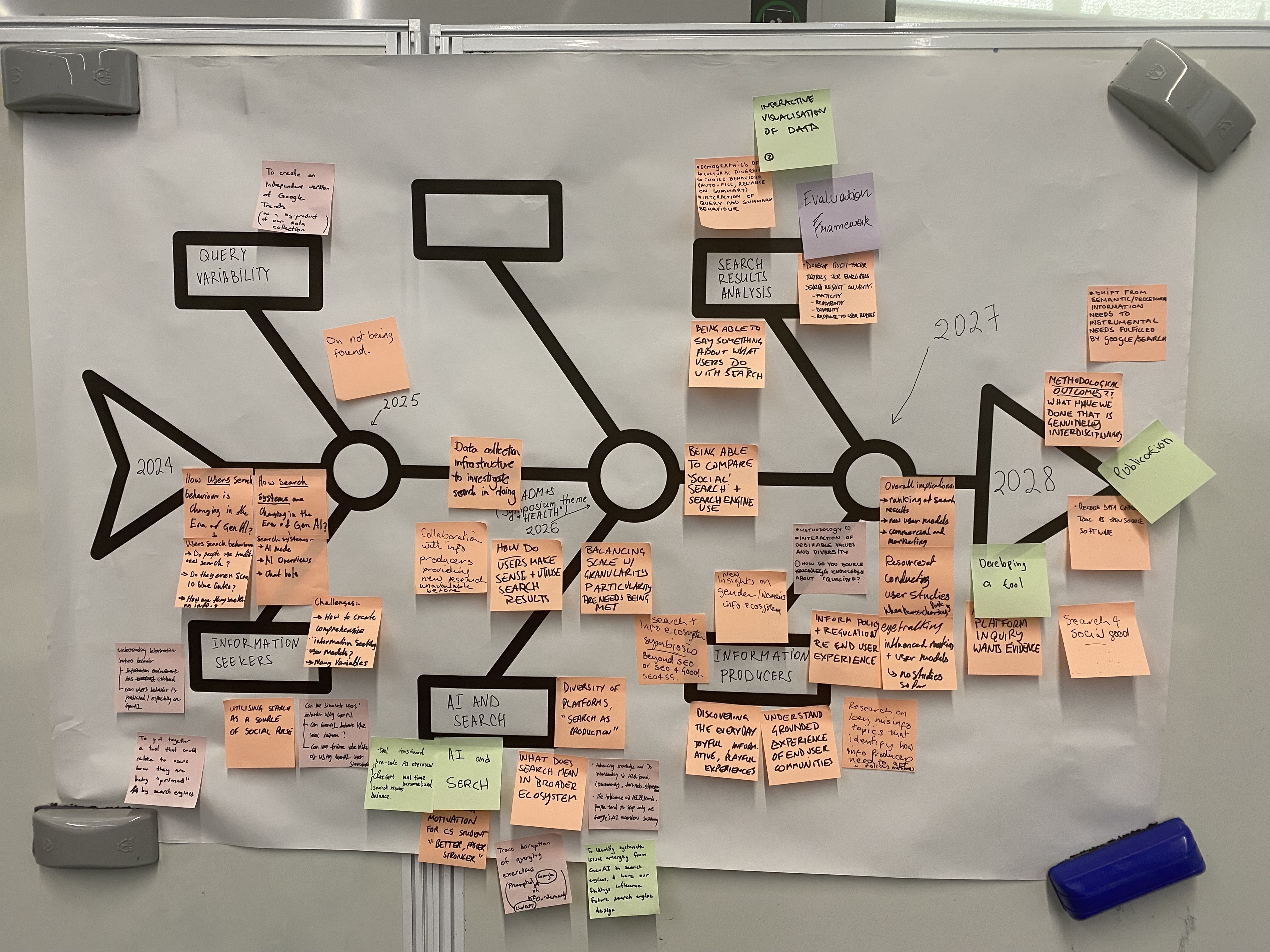
It was really exciting to be able to hear everyone's thoughts on the progress of Australian Search Experience 2.0 team. It looks like the project is evolving into something very comprehensive. We spoke a lot about how people people appear to gain instrumental rewards at the same time as fulfilling their semantic or procedural information needs. This is a topic I am really interested in!
Report on the 3rd Workshop on NeuroPhysiological Approaches for Interactive Information Retrieval (NeuroPhysIIR 2025) at SIGIR CHIIR 2025
The International Workshop on NeuroPhysiological Approaches for Interactive Information Retrieval (NeuroPhysIIR’25), co-located with ACM SIGIR CHIIR 2025 in Naarm/Melbourne, Australia, included 19 participants who discussed 12 statements addressing open challenges in neurophysiological interactive IR. The report summarizes the statements presented and the discussions held at the full-day workshop.
The basic idea of what I promoted in the attached report is that the speed, density, and volatility of an interface is known have predictable impacts on how people make decisions. I put forward task demands as a construct for computer science capturing how the architecture of decision-making couples with the architecture of the task. Users pursue goals, but the choice they perceive and take are constrained not only by the available options, but additionally by the cognitive resources they can afford in the moment. In other words, the architecture of decision-making couples with the architecture of the task. This report bridges split-second chioces and longer-horizon learning by inverting the user's generative model of the task, and provides measurable constructs, such as priors, learning rates, and uncertainty from behaviour to reveal when interfaces change behaviour. The payoff is an adaptive design that detects overload and nudges users back toward accurate, less biased belief updating.
Papyrus (2025)
The scholarly record is increasingly fragmented: more than four million peer-reviewed papers now appear each year, yet mismatched metadata, discipline-specific jargon, and paywalls hinder efficient discovery. When the volume of information overwhelms a finite capacity, researchers must either spend months undertaking cross-disciplinary syntheses or retreat into an ever-narrower niche, fueling professional fatigue and the well-documented reasoning errors that accompany cognitive overload.
We re-frame this crisis as a tractable machine-learning problem. Transformer-based language models embed full-text articles in a shared semantic space, while citation graphs add complementary topological cues. Together these representations can automatically surface convergent findings, flag near-replications, and spotlight neglected intersections. Each of these tasks currently overwhelm manual review. Layering an adaptive recommender that infers a reader's evolving goals yields the benefit of passive discovery of high-utility papers as well as an explicit push toward serendipity, both measurable with standard ranked-retrieval and diversity metrics.
Papyrus is a desktop and mobile platform that atomises every article into fine-grained Units of Knowledge, or minimal, context-free propositions expressed in subject-predicate-object form. Each Unit inherits its parent article's embedding, enabling intra-paper summarisation and inter-paper synthesis through a two-stage pipeline (predicate-argument extraction followed by cosine-similarity clustering). Granularity adapts to expertise: novices see high-level explanatory Units, while domain experts receive technical Units that reveal citation pathways and unresolved contradictions.
Semester 1: Psychology of Everyday Thinking (1st year subject) — 2025
Began tutoring the course Psychology of Everyday Thinking for the first time, at the City Campus of RMIT University.
Dataset Sentiment Classifier for Experimental Stimuli (2025)
A new protocol is emerging in misinformation research that aims to improve the rigor of stimulus design. But pretesting statements for emotional or categorical content is often costly and places an undue burden on participants, who have to repeatedly evaluate large sets of stimuli simply to verify that they meet predefined criteria.
As a preliminary solution, machine learning offers a promising route for approximating human-like text perceptions. I've developed a simple tool on Kaggle that allows researchers to upload a dataset of statements and receive outputs categorizing each one by emotional sentiment and its intensity. Essentially, it serves as a user-friendly interface for psychological researchers without a technical background, providing access to a sentiment classifier without requiring extensive coding.
Warning: this method has not yet been validated against established psychological measures at the time of writing. Perhaps a future PhD project could take this further? Someone, pick it up!
Post-SWIRL’25 mini-conference (following the 4th SWIRL) — 2025

Brief recap and links coming soon.
Leveraging the serial position effect to enhance auditory recall for voice-only information retrieval (2024)
Prototype description and evaluation plan coming soon.
The role of conflict and alignment in shaping responses to polarizing factchecks (2024)
People often continue to endorse claims after fact-checks (the continued influence effect, CIE). Dominant accounts attribute CIE to a failure to detect conflict between prior beliefs and corrective evidence, or because, once they do notice, they respond in a reactive partisan-consistent way. In a 2×2 (Congruence × Truth) online experiment with N=200 Australian adults, we measured participant evaluations at two levels: rapid associations (Brief Implicit Association Test; BIAT) and normative judgments (self-report). We predicted that larger implicit–explicit discrepancies (IED) would magnify partisan-congruent processing if an identity-protective form of dissonance dominated. Contrary to prediction, while perceptions of statements were clearly shaped by partisanship and fact-checking robustly predicted belief updating, IED did not reliably moderate the degree of belief updating. Instead, higher overall source liking, indicated by alignment across measures, broadly dampened corrective shifts irrespective of congruence, suggesting that coherent intuitions about both preferred and nonpreferred sources set the weight of correction, not conflict between them. This pattern is consistent with conflict being registered at the statement–evidence level while source-level discrepancy remained inert. We propose that to increase item-level accuracy, corrections should generally suppress identity coactivation and keep sources peripheral so that judgments anchor themselves in statement-evidence coherence.
Semester 2: Cognitive Psychology (2nd year subject) — 2024
Began tutoring the course Cognitive Psychology for the first time, at the City Campus of RMIT University.
Semester 1: Philosophy & Methodology of Psychology (3rd year subject) — 2024
Began tutoring the course Philosophy & Methodology of Psychology for the first time, at the City Campus of RMIT University.
PhD Proposal — Impact of Information Environments on the Perception of Credibility (2024)
Relevance and credibility are shaped by the information environments people inhabit and the noise they encounter. Information environments range from feeds that consistently surprise the user to those that consistently affirm them, each altering attention and memory systems in distinct ways. Previous research has shown that noise, defined as inconsistent or distracting information, can disrupt attention, increase cognitive load, and reduce efficiency.
As algorithms increasingly become the main source of information globally, it is essential to investigate how the structure these algorithms impose on information affects the way individuals maintain and revise their beliefs, accounting for the varying presence of noise in these feeds. Understanding how these varying environments impact perception is key to unraveling the cognitive and neural mechanisms involved in human-information interaction.
The primary aim of this topic is to explore the relationship between different information environments and their impact on perceptions of credibility. Specifically, it seeks to investigate how various sequences affect information processing and beliefs regarding the specific information being sequenced. This is to examine the potentially disruptive effects of noise during credibility judgements and maintenance of states of cognitive control.
Previous research has revealed adaptive strategies employed by the meta-cognitive system in noisy environments. But as of yet, it is unknown whether these strategies are also utilized in algorithmically sequenced news information, potentially explaining key findings in studies of misinformation and the susceptibility of people to polarized narratives when such narratives confirm existing beliefs. These investigations seek to contribute to the body of literature tasked with developing strategies to moderate credibility perception in diverse information settings.