About

PhD Candidate at RMIT University & the ARC Centre for Excellence in Automated Decision-Making and Society (ADM+S) | ADM+S Australian Search Experience 2.0 | Sessional Tutor for Psychology
Computational Models of Cognition | Resource-Rational Analysis | Sequential Latent-state Learning | Human-Computer Interaction
Polarization | Misinformation | Belief-updating | Fact-checking
How do people update their beliefs? How should people update their beliefs? My work focuses on describing the limits and possibilities of human inference. By characterizing the constraints on the mechanisms people use to make sense of new evidence, we can better understand why people update their beliefs the way they do and how changes in the informational environment may make alternative inference strategies more feasible. I am particularly interested in using this method to evaluate and inform technology with logical and philosophical standards of rational decision-making, to help people optimally reason about information especially where technology shifts what kinds of reasoning are possible. This motivates my aim to model, design, and test sequencing rules for learning materials across learners who begin with similar versus diverse prior beliefs, testing how these starting points change which ordering yields the greatest and most reliable learning.
Probabilistic Bayesian approaches can model how exposure history builds associations that support rapid decisions without reconstructing a full causal model on every encounter. This helps predicting when a context supports reliance on coarse predictive categories about factors distinct from reasoning about the proposition itself. I am currently applying this framework to political messages and news, especially propositions that are misleading, emotionally charged or politically motivated. In large-scale online experiments, we can vary features of exposure sequences and measure when people rely on fast, intuitive judgments versus more deliberative evaluation, and how beliefs change in response.
This sets up a research programme, because algorithms structure both what people see and the order in which they see it, and as such, possibly shape the statistics that these fast policies learn. Embedding learner models into information systems can let us adaptively place corrections or explanations at moments most likely to disrupt responding through habits and instead encourage deliberation.
Feedback History Constrains Confidence and Truth Discernment Through Overhypothesis Learning (2026)
Given the vast space of potential retrieval targets in memory, credibility assessment requires deciding what is important to retrieve. We propose a model of bounded credibility inference in which people maintain an overhypothesis about the feedback structure of the information environment, learned from the recent balance of affirmation and refutation, that regulates search breadth. On this view, overconfidence and knowledge neglect arise when confidence is based on a posterior constrained by this higher-order belief rather than solely by evidence bearing on the focal proposition. We tested this account in a news-headline decision task that manipulated the confirmation rate of feedback to induce different histories of inferential uncertainty. Across two studies, we examined whether these learned policies persist when feedback is removed or attenuate when fully veridical feedback resumes. We found that [RESULT 1] and [RESULT 2], consistent/inconsistent with the view that confidence in truth discernment reflects a learned summary of inferential uncertainty shaped by feedback history. Model comparisons showed that [MODEL RESULT, if true], with implications for how information environments can support calibrated confidence in credibility assessment.
AMPC2026 (2026)
I attended the Australasian Mathematical Psychology Conference (AMPC) 2026, held at the National University of Singapore (NUS), Singapore.
View the slides I presented (PDF)

Thoughts on "the mind" and ASPP 2025 Melbourne (2025)
I want to put down some loosely constellated reflections on the Australasian Society for Philosophy and Psychology 2025 Conference (which I just got back from), mainly the questions it raised that I rarely have to address in my work. Rather than answering those questions directly, I want to have a guess at why they might not come up that often for me. These reflections were prompted in particular by Dr Cammi Murrup-Stewart’s talk, in which she argued that research relationships always negotiate and delimit what knowledge can be discovered, and called for a more deliberate recognition of the hidden assumptions underlying relationships we have long taken as simply given. She spoke about how deepening our awareness of our relationships with our teams and the people involved in our work allows us to deepen the knowledge we can uncover; and, conversely, how deepening our awareness of the assumptions in our knowledge can open up new, potentially closer modes of relating. Here, I want to focus on this second point, by offering an up-front attempt at a conscious reflection on the assumptions that underpin my work.
I am an Anglo-Australian, born to Anglo-Australian parents who both dedicated their careers to education, one as a school principal and the other as a teacher. They were, respectively, the son of a clerk and a high-school teacher, and the daughter of a meat carver and a truck driver. Both sides of my family emigrated to Australia after the First World War, from Ireland, Scotland, and France. I therefore come from a Western background, in which my heritage and my education are tensely interlinked.
Against this background, I reflect on what I think is possible in the world and realise that my own position in relation to knowledge is shaped by a certain framework. This framework centres on efficacy in the pursuit of contingent rewards, and on an assumption that no reward motivates human behaviour apart from those causally derived from genetics or from what we learn from the environment. Both are taken to structure a set of states accessed only via prior states, and by modelling those states one aims to obtain rewards at both the individual and collective level.
But I wonder, is there a type of motivation that could not be captured by that? Obviously, because I am only looking for empirical evidence, we naturally have to limit ourselves to something we can agree is true, and perhaps it takes something physically in our environment to garner enough consensus that we can call it empirical. A fleeting, deeply personal moment in imagination is not enough to get us there. This process of consensus is all too often engaged without concern for the possibility that, by structuring these states into causes represented by much-debated theoretical stand-ins, we may absent-mindedly treat those stand-ins as if they preserved the very complexity for which they were originally coined.
Initially, I took my experiments to be tools for inferring stable properties of the mind. Thinking more carefully about this however, especially in light of Dr Murrup-Stewart’s talk, I now see that I may be relating to the mind in precisely the way the framework itself encourages, as something that takes on the structure built into experiments. The tasks used to capture psychological concepts may be as much about the mind’s ability to take on the structure of the task as about any pre-existing mental property. The data I collect can therefore be attributed as much to the task as to the mind. I have little way of knowing whether the task engages an enduring property, or something constructed ad hoc for this particular setting. All I can say, then, is that I can model the environment computationally, and assume that the mind takes up that model in the form of what I describe as mapped items and outcomes, or associations. In other words, associations may be as much a product of the experimental environment as of anything intrinsic to the mind. I hesitate to attribute exactly that structure to “the mind itself”, whether as a model that precedes exposure to the environment, or as one that arises from it. For now, I treat such models as sufficient only for that purpose, and I want to be explicit that this is a constraint of my approach.
In this sense, experimental environments construct a relationship to the mind that resembles the research relationships Dr Murrup-Stewart described. They negotiate and delimit what can appear as the mind in its outcome. The mind, embedded in the experimental environment, is penetrated by the patterning of the scenarios it is asked to behold. I can therefore reframe cognitive inferences as describing a structure or subjectivity that is technically owned by the environment, and only contingently by the participant. But at the same time, I really am tempted to talk about an “interior” environment that can sequence percepts in such a way that a subject emerges independently of the task design, the environment encountered, and the genes encoded. To approach that, I would again reach for computational tools to describe how patterns might be extracted from sequences. But how could I do so? It is partly for this reason that I leave out step three of Marr’s process in my own work and replace it with something that keeps the focus on this environment–mind relationship rather than on a fully specified internal representation.
What this brings into focus is a genuine problem for me: if my methods and relationships help constitute what I call “the mind”, how can I claim to be inferring anything beyond those methods and relationships? Causality, in my current framing, is largely described in terms of genetics and environment, and I risk treating all patterns as if they belong only to those domains. But causality cannot be assessed separately from questions about which causes ought to matter. The spaces occupied by morals, relationships, and even ancestral connections also enact causes from a position with as much reality as those imposed by genetics or our environment, and, as such, we are required to attribute the patterns we extract to an “I”, a “you”, and a “them”. Achieving that, valuing the rewards of contingencies not merely because they marginally relate to some intended outcome, is something my current viewpoint is not well equipped to do. It is incredibly difficult to understand the limits of such things, perhaps because they are the very stuff from which I have been constituted since birth. There may be causes that have always existed in eternity, much like mathematical truths, and yet, because they have not appeared in time as structured sequences, we can say nothing about them. From within my framework, behaviour becomes the activity of something I can only treat as an outcome of something else. The more I reflect on this, the more I see that my approach may be unable, on its own, to answer the question of what the mind is apart from the experimental and relational structures through which it is encountered. Rather than resolving that tension here, I want to name it as a limit within which my work currently operates, and to leave open the question of whether there is any way to infer “the mind” without such structures at all.
I presented a poster (see it here)

ADM+S hackathon: navigating the “wicked problems” of search (2025)
We just finished the ADM+S hackathon having won the second day, or the solution phase. The hackathon really felt like a top example of what I imagine they wanted to come from ADMs+ when they started it in the first place. Our team was a mix of qualitative and quantitative researchers, from computer science, media/comms, AI ethics, and myself in psychology, and I believe our solution really reflected everyone's taste.
I started with a lot of preconceived ideas, mainly inspired by one of my favourite papers, "The Two Settings of Kind and Wicked Learning Environments," which I really recommend you read. My inspiration was initially centered on the idea that an environment can be "wicked" in the sense that it is structured in such a way that the probabilistic relationships one has learned previously no longer apply. This negatively impacts inference, because people are acting on models of the environment without knowing that it is a model separate from the one in which they now take action. Funnily enough, I really appreciate my team taking me away from simply creating something based on what I already know, in environments I am already used to. What I learned previously didn't apply here, and hopefully I'm smarter for it. I'll attach the related paper once it's finished.
Below is an image of me trying to scare the other teams by holding a book filled with equations I don't really understand.

Using a psychological method to increase performance of LLM for relevance judgement and ranking tasks (2025)
Summary and links coming soon.
When order shapes belief: sequence design for bounded agents (2025)
People rarely encounter information in isolation. Instead, they encounter it through algorithmic feeds that embed items within sequences and contexts that shape their salience, credibility, and integration with prior beliefs. We argue that human learning from recommender systems and the ways it may differ, can be understood by considering credibility as a computational problem of inference over time. The learner must identify reliable cues and sources, allocate attention, and update beliefs under constraints, which constitutes a computational problem that the human learner is optimized to detect and exploit. We claim that this problem acquires a rough solution from three fundamental control systems that the brain uses to maximize functioning across two desirable but competing performance dimensions: speed-accuracy, stability-flexibility, and generalization-multitasking. If improvements on one predictably degrades the other, then sequences that push the system toward speed, stability, or divided attention should yield predictable biases in belief updating. These trade-offs shape belief updating under sequenced exposure and serve to explain common findings in the misinformation and digital persuasion literature.
Clickbait nudges social media away from accuracy and toward partisan bias (2025)
Prior work shows that accuracy prompts reliably shift attention towards more careful decision-making, reducing belief in misinformation. Variation in headline format, beyond its content, may likewise act as a prompt that changes which evaluative dimension is applied during veracity assessment. We formalize this question using a rational inattention framework in which people selectively allocate limited evidence accumulation across multiple evaluative dimensions. However, this account predicts either that sensational (“clickbait”) cues may make evidence utilization more difficult and encourage reliance on polarized beliefs, or by signalling uncertainty, they may elicit stricter decision criteria and reduce false endorsements. In total, 82 participants from the U.S. judged the veracity of 64 headlines, varying in political congruence (congruent/incongruent) and truth (true/false), and were randomly assigned either to view clickbait or neutral formats. Results showed that both classification accuracy and response time exhibited a significant three-way interaction among headline style, congruence, and truth. For the clickbait condition, judgements aligned more strongly with political congruence, leading to more correct judgements for aligned headlines and fewer for conflicting ones. This pattern weakened under neutral formatting. A hierarchical drift-diffusion model indicated that clickbait changed how evidence was accumulated, without making people more cautious or pre-biased at the start. Interpreted through rational inattention, these results suggest that clickbait makes it less worthwhile to accumulate evidence on the accuracy dimension. When accuracy evidence becomes noisier, partisanship is selected as an alternative, and judgments increasingly follow political congruence rather than truth.
Making accuracy easier: credibility perceptions as a latent cause assignment problem (2025)
The challenge of identifying reliable content amid widespread falsehoods requires a capacity for well-calibrated credibility judgments. We propose that humans address this challenge using statistical learning-the same cognitive process that helps us acquire language and recognize patterns. However, this adaptive mechanism may backfire in algorithmically curated information environments, leading to increased polarization and susceptibility to misinformation. We first outline a latent-cause model of credibility perception, which broadly describes the impact of structure learning, allowing people to categorize information based on recurring patterns (source identity, emotional tone, in-group signals) and then use these categories as shortcuts when evaluating new information. While this process is cognitively efficient, it can make users more vulnerable to misinformation that matches their learned patterns and more resistant to corrections that violate them. We present a Bayesian framework linking environmental statistics to belief formation, propose three testable predictions, and outline experimental protocols for studying these phenomena in controlled settings.
Thoughts on A.I. and Offgrid online (2025)
Like everyone without a vested interest in its success, I'm very skeptical of A.I.'s ability to contribute positively, or even to help people contribute creatively. It feels strongly like we're being sold a second tech bubble while many of us are still trying to kick the addiction to the first. Still, I recently got a free year of Gemini through a student account, and curiosity won. I wanted to see whether these tools could actually help me be creative. The broswer extension I ended up building, Offgrid/online is my small attempt to test that.
People reminisce about the pumping up of the first tech bubble, or the early days of the web, and talk about it as a place unrestricted by tollways and corporate border patrols that have since been set between ourselves and our intentions. Back then, your name didn't have to take a detour on the way from the computer to the printer, first travelling across the desks of the world's top five richest companies. So I catch myself thinking: are we in an equivalent early moment with A.I., before it inevitably also turns into a watered-down slot machine of advertisements, the way the web largely has? The early tnternet is remembered as a time of extreme creativity, partly because of survivorship bias, and partly because it was before they really figured out how to monetize the thing.
We seem to be in the same spot with A.I. I suspect it's why I suddently find myself with free access. The companies behind these systems are hoping either I stumble onto the use case that earns them trillions, or that I become sufficiently addicted to the current product, and they can quietly usher in a replacement for "innovation" with what they call "engagement". While I was playing around, I made a small browser extension which I call Offgrid/online. It's buggy and only a stand-in for what I wanted to build, but it is fully AI-coded, and AI-decorated. I generated its images iteratively using Nano Banana and then reduced their resolution into pixel art.
I keep circling back to the first tech bubble because, if there's a lesson in it, it's that increased resources do not automatically produce increased diversity of choice. The internet was sold to us as a vast sampler of ideas we would never otherwise encounter, something that would give everyone a richer, more nuanced worldview. But we know now that that didn't happen. We were mostly enabled to become more intensely what we already were. I suspect we'll see something similar in the age of A.I.: people becoming the most themselves they have ever been, their particular flaws and talents taken all the way to their nth degree. But what if it didn't have to be that way? What if I could become the person I had hoped to be, rather than the one my habits keep rehearsing?
This will seem a little tangential, but I get a little confused when I hear someone say that something "explained what they had always known." You hear that on the internet sometimes. On the one hand, its a sign that human communication can, despite my doubts, for a moment bridge the unnamable problem of always seeing things through one persons eyes. We will never find ourselves temporarily awakened submerged in the dense sincerity of all it is to be the person observing ones own thoughts, and yet sometimes you read something, or see something happen in time, that helps you feel a little less alone in your head. On the other hand, it suggests we carry around whole territories of knowledge that we've never really elaborated or ever questioned. Indeed, I might spend my life slicing off parts of myself, those parts that feel like signposts with my name and a little pride nailed to them, only to realise they were acquired from other people, who acquired them from other people, who in a broader sense inherited them from the ex-tabula rasa that is the culture as such.
It often goes like this: you read something that touches a core part of you, and it feels like it's been coughed up from somewhere that unknowingly choked you on the air you breathe. That feels good, breathing properly again. But I notice I get almost the same phenomenological jolt when an idea I never quite had is completed by something I read. A circuit I didn’t know existed suddenly closes, and there it is on the page, as if it had been waiting for me to arrive. So which is it?
It is only through work, real work, can that loop be acknowledged and perhaps rewired. I've felt that feeling with so many things. I had it happen with A.I. I have it happen with almost every news headline. It's as if I already know, somewhere, how I'm supposed to feel about whatever appears, even if that feeling is digust. Each story slots neatly into some smug internal narrative about the world, written long ago, to the point that I sometimes forget to read the words in front of me. I know A.I. is swept up in a greed-storm. I know that, at base, I probably just want to be entertained and well-fed, and that these systems will be tailored to those ends. The strange thing is: I know all of this, and I still want to try to make something good here. I want to think something I wouldn't already have thought in some minor variation. I want to search the library of human knowledge without walking in clutching the book I already intend to find. I want the words on the page to have a life I didn't give them. Offgrid Online is my attempt to move, however slightly, in that direction.
Offgrid Online is a browser extension that visualises the environmental cost of your computer use and the data centres that power it. Your activity is converted into research-based CO₂ estimates and applied in real time to a simulated micro-forest. You can restore the forest by making small donations to partnered environmental charities.
The tool watches for a few specific types of activity from your browser. For each category, AI interaction, media streaming, page loads, and general browsing, two pieces of information are combined. First, an estimate of the computer's total electricity use while active, and second, an estimate of the load on data centres and networks. And yes... an estimation is made for what the tool itself is also expected to generate. If I'm going to use A.I. to think about the cost of all this infrastructure, the least I can do is let it count itself too, so I don't forget that it's not outside the system I'm criticising, but one more machine wired into it, or, at least, if only to keep myself from mistaking it for anything cleaner or wiser than the system that built it.
ADM+S Symposium — Automated social services: Building inclusive digital futures (2025)

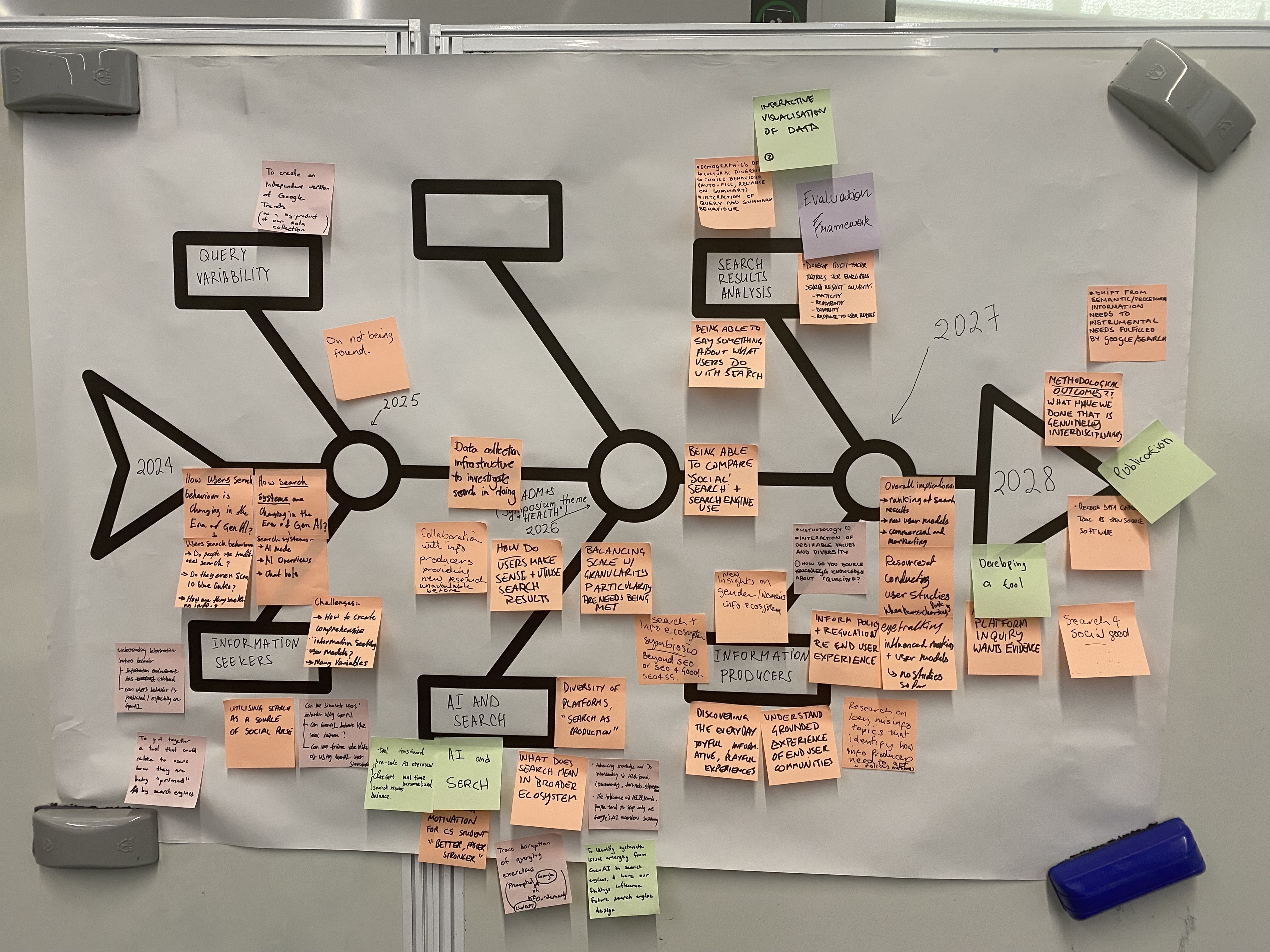
It was really exciting to be able to hear everyone's thoughts on the progress of Australian Search Experience 2.0 team. It looks like the project is evolving into something very comprehensive. We spoke a lot about how people people appear to gain instrumental rewards at the same time as fulfilling their semantic or procedural information needs. This is a topic I am really interested in!
Report on the 3rd Workshop on NeuroPhysiological Approaches for Interactive Information Retrieval (NeuroPhysIIR 2025) at SIGIR CHIIR 2025
The International Workshop on NeuroPhysiological Approaches for Interactive Information Retrieval (NeuroPhysIIR’25), co-located with ACM SIGIR CHIIR 2025 in Naarm/Melbourne, Australia, included 19 participants who discussed 12 statements addressing open challenges in neurophysiological interactive IR. The report summarizes the statements presented and the discussions held at the full-day workshop.
The basic idea of what I promoted in the attached report is that the speed, density, and volatility of an interface is known have predictable impacts on how people make decisions. I put forward task demands as a construct for computer science capturing how the architecture of decision-making couples with the architecture of the task. Users pursue goals, but the choice they perceive and take are constrained not only by the available options, but additionally by the cognitive resources they can afford in the moment. In other words, the architecture of decision-making couples with the architecture of the task. This report bridges split-second chioces and longer-horizon learning by inverting the user's generative model of the task, and provides measurable constructs, such as priors, learning rates, and uncertainty from behaviour to reveal when interfaces change behaviour. The payoff is an adaptive design that detects overload and nudges users back toward accurate, less biased belief updating.
Papyrus (2025)
The scholarly record is increasingly fragmented: more than four million peer-reviewed papers now appear each year, yet mismatched metadata, discipline-specific jargon, and paywalls hinder efficient discovery. When the volume of information overwhelms a finite capacity, researchers must either spend months undertaking cross-disciplinary syntheses or retreat into an ever-narrower niche, fueling professional fatigue and the well-documented reasoning errors that accompany cognitive overload.
We re-frame this crisis as a tractable machine-learning problem. Transformer-based language models embed full-text articles in a shared semantic space, while citation graphs add complementary topological cues. Together these representations can automatically surface convergent findings, flag near-replications, and spotlight neglected intersections. Each of these tasks currently overwhelm manual review. Layering an adaptive recommender that infers a reader's evolving goals yields the benefit of passive discovery of high-utility papers as well as an explicit push toward serendipity, both measurable with standard ranked-retrieval and diversity metrics.
Papyrus is a desktop and mobile platform that atomises every article into fine-grained Units of Knowledge, or minimal, context-free propositions expressed in subject-predicate-object form. Each Unit inherits its parent article's embedding, enabling intra-paper summarisation and inter-paper synthesis through a two-stage pipeline (predicate-argument extraction followed by cosine-similarity clustering). Granularity adapts to expertise: novices see high-level explanatory Units, while domain experts receive technical Units that reveal citation pathways and unresolved contradictions.
Semester 1: Psychology of Everyday Thinking (1st year subject) — 2025
Began tutoring the course Psychology of Everyday Thinking for the first time, at the City Campus of RMIT University.
Dataset Sentiment Classifier for Experimental Stimuli (2025)
A new protocol is emerging in misinformation research that aims to improve the rigor of stimulus design. But pretesting statements for emotional or categorical content is often costly and places an undue burden on participants, who have to repeatedly evaluate large sets of stimuli simply to verify that they meet predefined criteria.
As a preliminary solution, machine learning offers a promising route for approximating human-like text perceptions. I've developed a simple tool on Kaggle that allows researchers to upload a dataset of statements and receive outputs categorizing each one by emotional sentiment and its intensity. Essentially, it serves as a user-friendly interface for psychological researchers without a technical background, providing access to a sentiment classifier without requiring extensive coding.
Warning: this method has not yet been validated against established psychological measures at the time of writing. Perhaps a future PhD project could take this further? Someone, pick it up!
Post-SWIRL’25 mini-conference (following the 4th SWIRL) — 2025

Brief recap and links coming soon.
Leveraging the serial position effect to enhance auditory recall for voice-only information retrieval (2024)
Prototype description and evaluation plan coming soon.
The role of conflict and alignment in shaping responses to polarizing factchecks (2024)
People often continue to endorse claims after fact-checks (the continued influence effect, CIE). Dominant accounts attribute CIE to a failure to detect conflict between prior beliefs and corrective evidence, or because, once they do notice, they respond in a reactive partisan-consistent way. In a 2×2 (Congruence × Truth) online experiment with N=200 Australian adults, we measured participant evaluations at two levels: rapid associations (Brief Implicit Association Test; BIAT) and normative judgments (self-report). We predicted that larger implicit–explicit discrepancies (IED) would magnify partisan-congruent processing if an identity-protective form of dissonance dominated. Contrary to prediction, while perceptions of statements were clearly shaped by partisanship and fact-checking robustly predicted belief updating, IED did not reliably moderate the degree of belief updating. Instead, higher overall source liking, indicated by alignment across measures, broadly dampened corrective shifts irrespective of congruence, suggesting that coherent intuitions about both preferred and nonpreferred sources set the weight of correction, not conflict between them. This pattern is consistent with conflict being registered at the statement–evidence level while source-level discrepancy remained inert. We propose that to increase item-level accuracy, corrections should generally suppress identity coactivation and keep sources peripheral so that judgments anchor themselves in statement-evidence coherence.
Semester 2: Cognitive Psychology (2nd year subject) — 2024
Began tutoring the course Cognitive Psychology for the first time, at the City Campus of RMIT University.
Semester 1: Philosophy & Methodology of Psychology (3rd year subject) — 2024
Began tutoring the course Philosophy & Methodology of Psychology for the first time, at the City Campus of RMIT University.
PhD Proposal — Impact of Information Environments on the Perception of Credibility (2024)
Relevance and credibility are shaped by the information environments people inhabit and the noise they encounter. Information environments range from feeds that consistently surprise the user to those that consistently affirm them, each altering attention and memory systems in distinct ways. Previous research has shown that noise, defined as inconsistent or distracting information, can disrupt attention, increase cognitive load, and reduce efficiency.
As algorithms increasingly become the main source of information globally, it is essential to investigate how the structure these algorithms impose on information affects the way individuals maintain and revise their beliefs, accounting for the varying presence of noise in these feeds. Understanding how these varying environments impact perception is key to unraveling the cognitive and neural mechanisms involved in human-information interaction.
The primary aim of this topic is to explore the relationship between different information environments and their impact on perceptions of credibility. Specifically, it seeks to investigate how various sequences affect information processing and beliefs regarding the specific information being sequenced. This is to examine the potentially disruptive effects of noise during credibility judgements and maintenance of states of cognitive control.
Previous research has revealed adaptive strategies employed by the meta-cognitive system in noisy environments. But as of yet, it is unknown whether these strategies are also utilized in algorithmically sequenced news information, potentially explaining key findings in studies of misinformation and the susceptibility of people to polarized narratives when such narratives confirm existing beliefs. These investigations seek to contribute to the body of literature tasked with developing strategies to moderate credibility perception in diverse information settings.